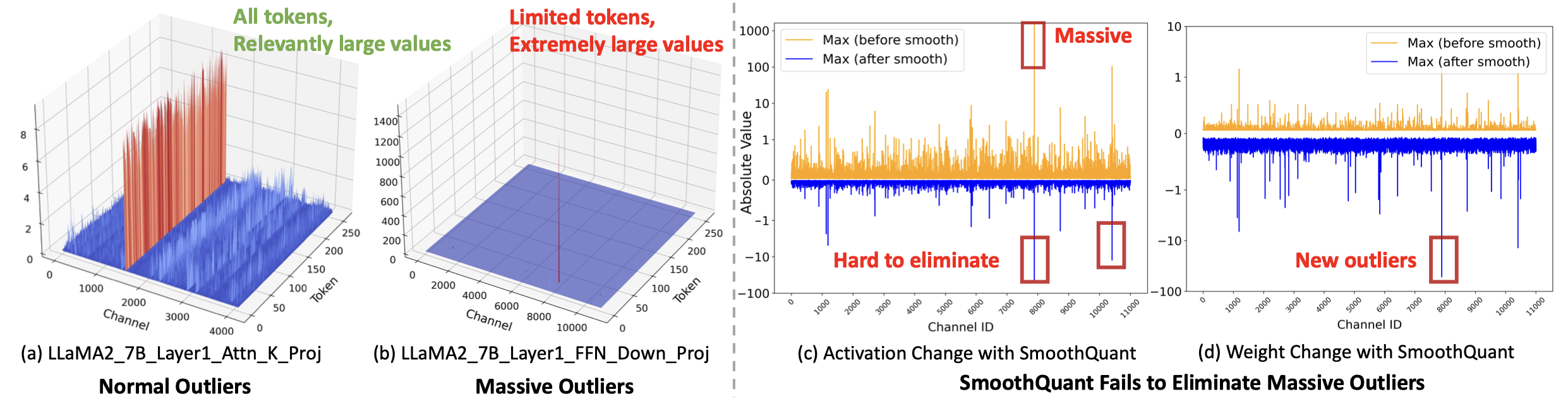
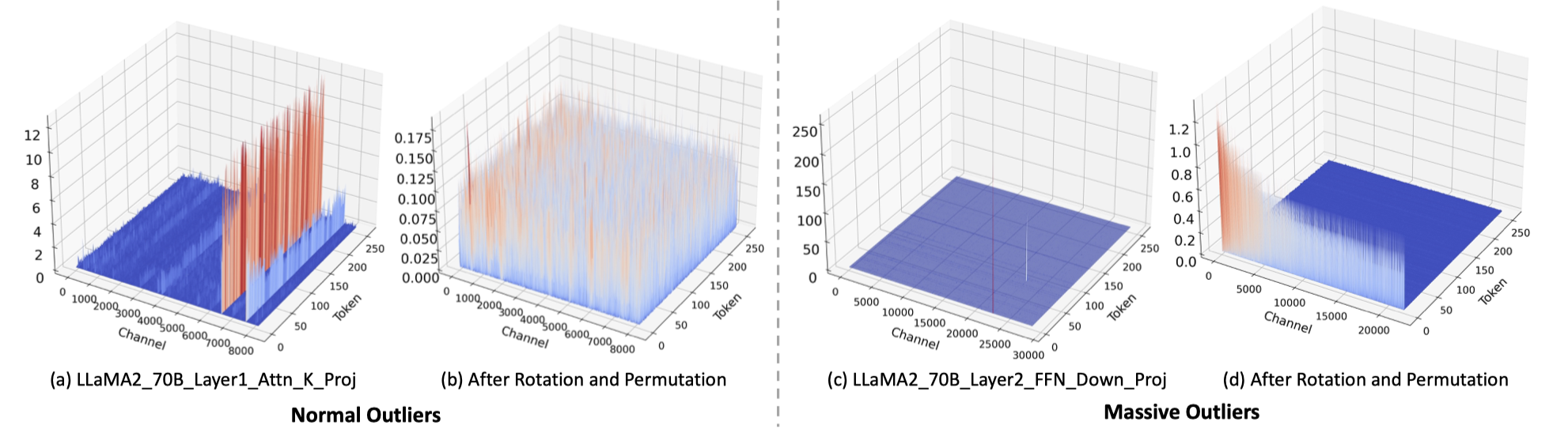
Quantization of large language models (LLMs) faces significant challenges, particularly due to the presence of outlier activations that impede efficient low-bit representation. Traditional approaches predominantly address Normal Outliers, which are activations across all tokens with relatively large magnitudes.
However, these methods struggle with smoothing Massive Outliers that display significantly larger values, which leads to significant performance degradation in low-bit quantization.
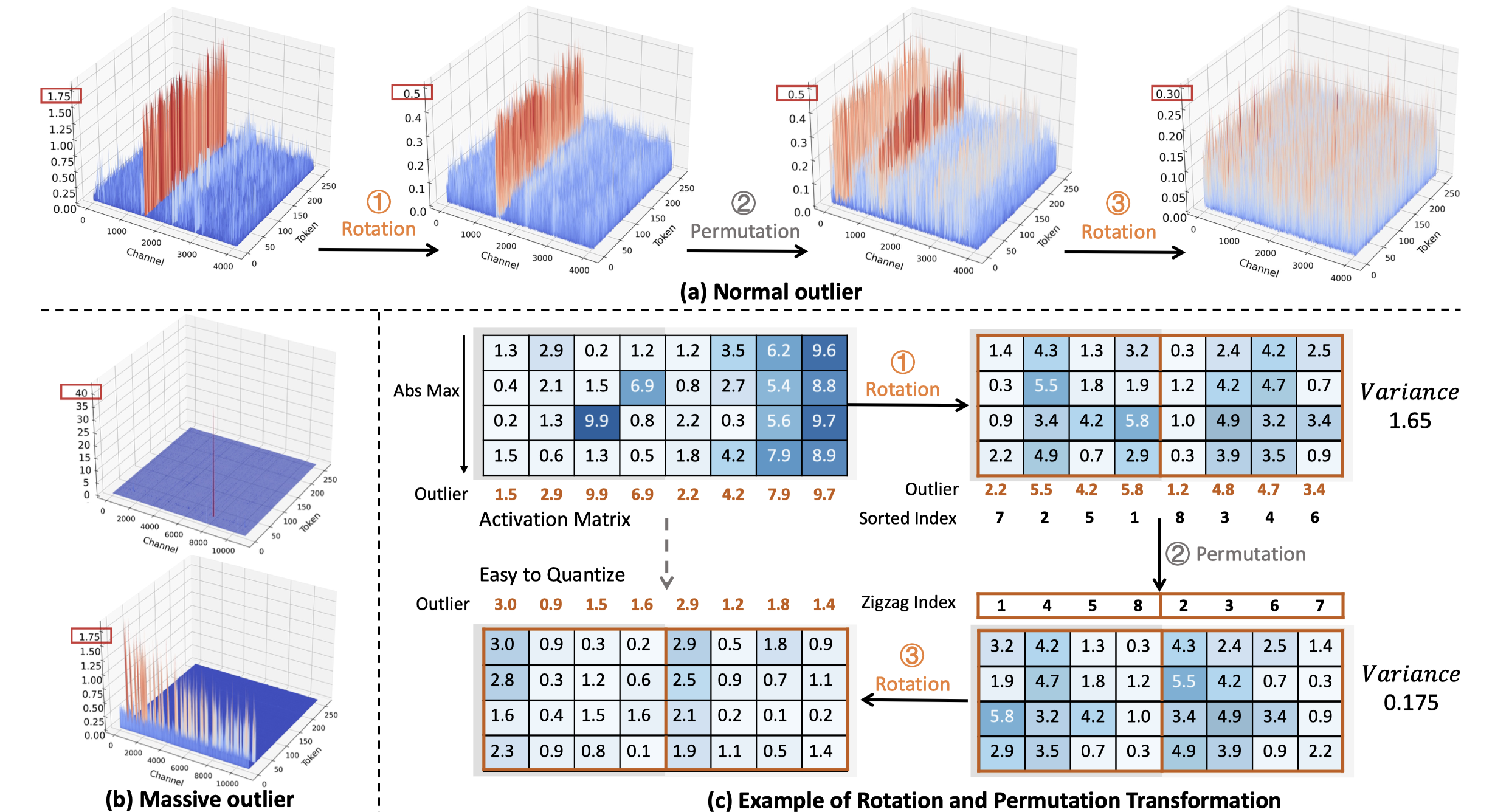
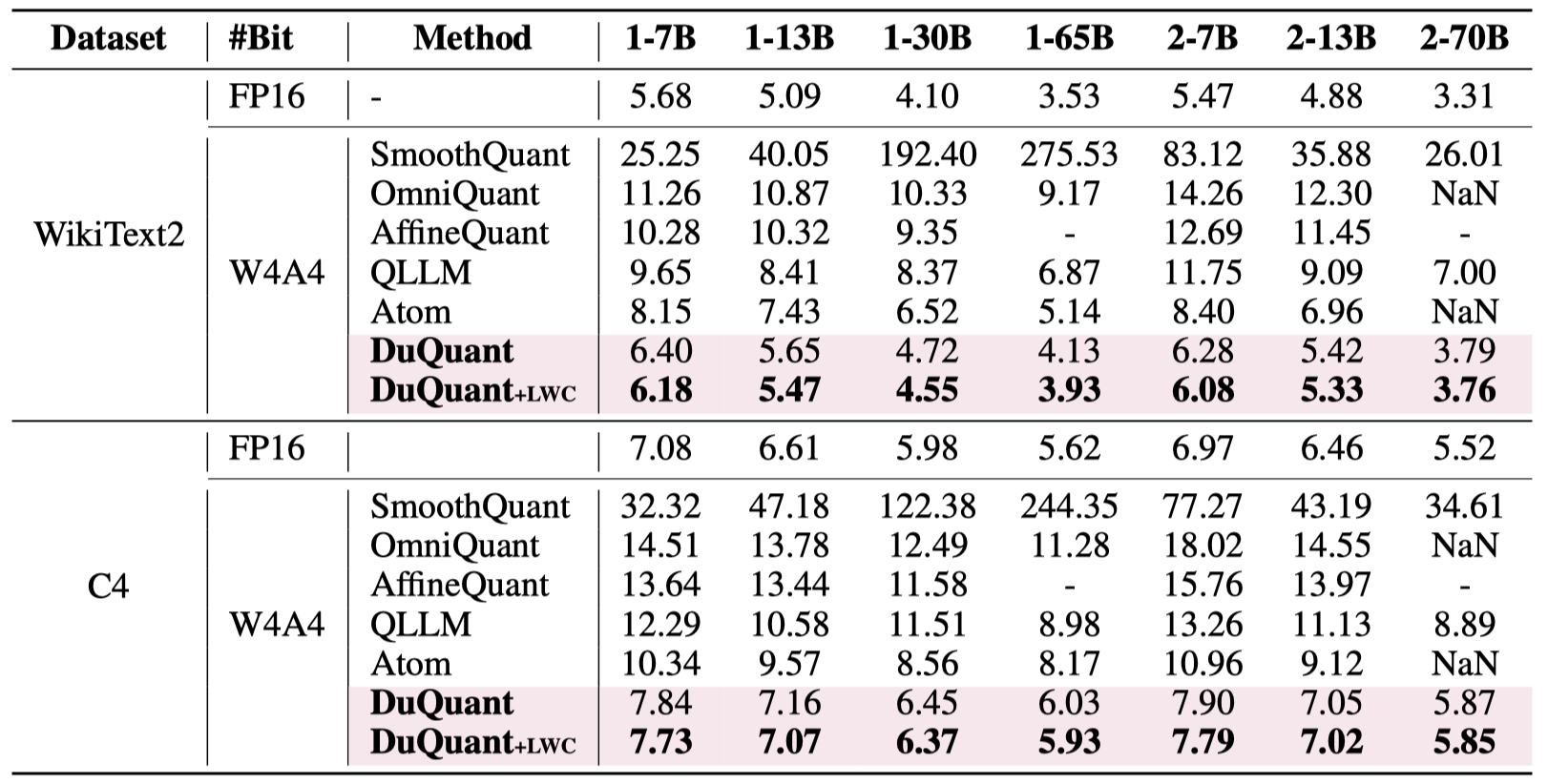
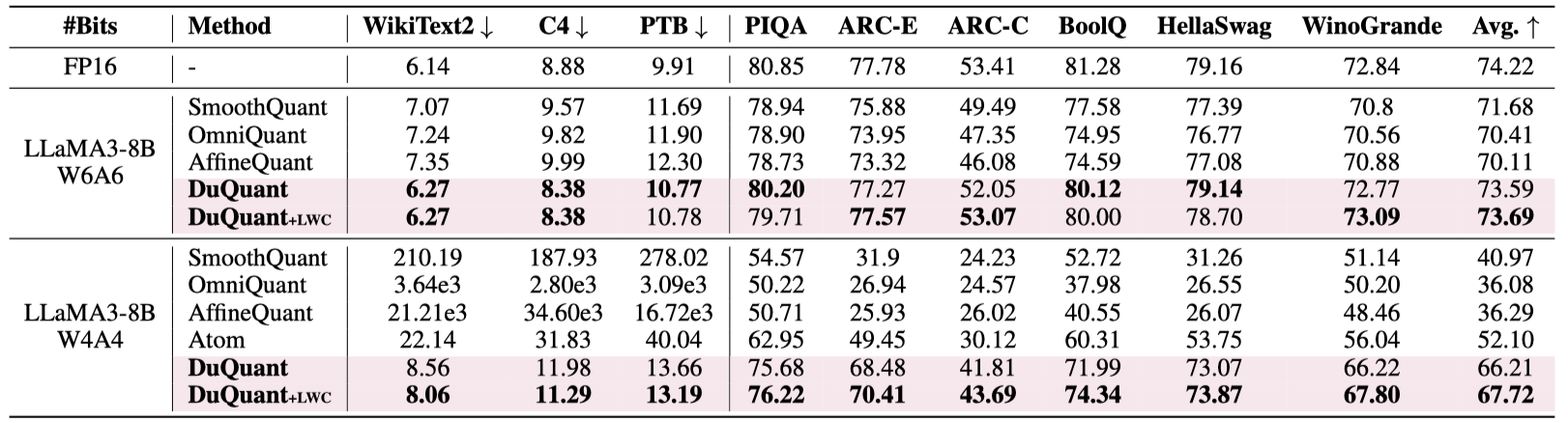
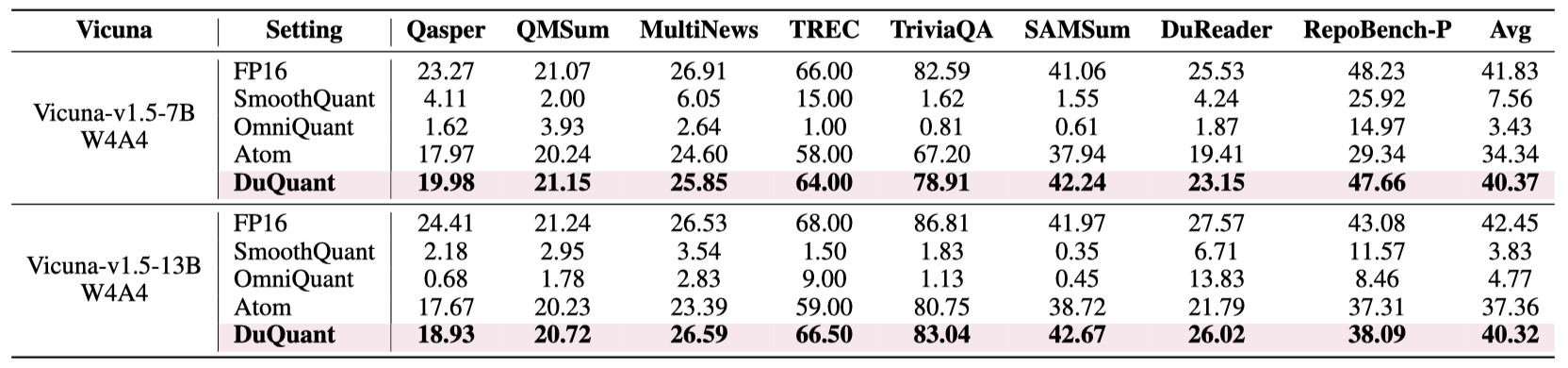
In this paper, we introduce DuQuant, a novel approach that utilizes rotation and permutation transformations to more effectively mitigate both massive and normal outliers. First, DuQuant starts by constructing the rotation matrix, using specific outlier dimensions as prior knowledge, to redistribute outliers to adjacent channels by block-wise rotation. Second, We further employ a zigzag permutation to balance the distribution of outliers across blocks, thereby reducing block-wise variance. A subsequent rotation further smooths the activation landscape, enhancing model performance. DuQuant establishs new state-of-the-art baselines for 4-bit weight-activation quantization across various model types and downstream tasks.